
TL;DR / Key Takeaways
- DevOps implementation services transform the migration from legacy to cloud into a step-by-step and measurable program rather than a risky tooling exercise.
- The roadmap guides through discovery, cloud foundations, CI/CD, IaC, observability and DevSecOps governance.
- Assessment, KPIs, pilot pipelines, IaC modules, monitoring and runbooks should be the primary focus for the first 90 days.
- The biggest failure risks are taking a tool-first approach, automating only part of the process, delaying security, low adoption and inadequate handover.
- Most teams outsource cloud foundations, golden pipelines, IaC templates, security automation, and observability design.

Releases shouldn’t feel like a high-stakes game where everyone holds their breath, rolls back at midnight, and hopes the “one server” that nobody owns doesn’t fail. However, for teams managing legacy systems, delivery remains reliant on manual runbooks, shared environments, fragile deployment scripts, and more – particularly when migration to the cloud introduces new moving parts.
This guide lays out a practical roadmap for DevOps implementation services specifically in a legacy-to-cloud environment, including the phases needed to undertake, the deliverables to look for, typical timelines, cost drivers, common implementation pitfalls and how to evaluate a partner without worrying about it. You’ll walk away with a plan you can actually execute—not a tool list.
What Are DevOps Implementation Services? Why Is Implementation Crucial?
DevOps implementation services are the structured work required to make software delivery repeatable, automated, secure, and observable—across people, process, and platform. The goal isn’t “using DevOps tools.” The goal is building a delivery system that reduces risk while increasing speed.
Implementation matters because DevOps improvements are interdependent. A faster pipeline without testing gates increases change failure rate. Infrastructure automation without governance increases cloud sprawl. Monitoring without incident workflows creates alert fatigue. Done properly, implementation aligns:
- People & operating model (ownership, on-call, collaboration, enablement)
- Process (release strategy, change control, incident response, postmortems)
- Platform & automation (CI/CD, Infrastructure as Code, environments, policy-as-code)
- Security & compliance (shift-left controls, audit evidence, access governance)
- Reliability practices (SLOs, dashboards, runbooks, capacity planning)
For legacy-to-cloud migration, implementation is crucial because you’re changing where systems run and how they’re shipped. Without a plan, teams often migrate infrastructure first and discover delivery and reliability issues later—when downtime is most expensive.
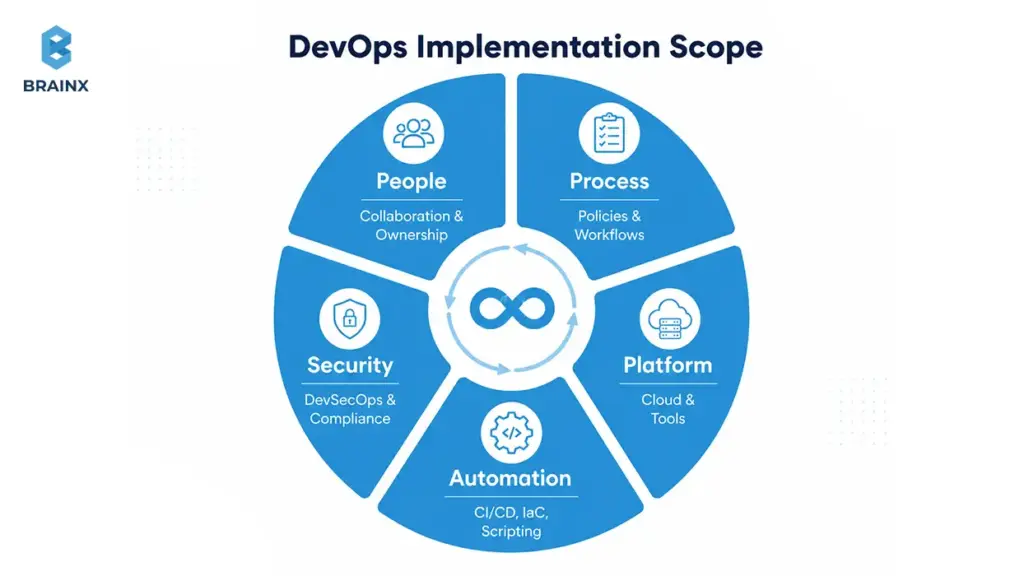
DevOps Consulting vs Implementation vs Managed DevOps
DevOps consulting & implementation services typically bundle advisory plus hands-on delivery—meaning you get a roadmap and the team to build it. The differences matter when you’re budgeting and setting expectations:
- Consulting (advisory): assessment, recommendations, target architecture, backlog, governance model. Useful if you have a strong internal platform team ready to execute.
- Implementation: execution of pipelines, IaC, cloud foundations, observability, and security automation—plus documentation and enablement. Best when you need outcomes quickly.
- Managed DevOps: ongoing operation of CI/CD, cloud infrastructure, monitoring, and incident response support. Best when internal capacity is limited or you want 24/7 coverage.
If your legacy estate is complex (multiple apps, shared databases, compliance constraints), a hybrid approach—advisory + build + a short managed period—often de-risks the transition.
What’s Included in DevOps Implementation Services
A real engagement is defined by deliverables, not tool names. Strong DevOps implementation services include a blend of strategy, build work, and operationalization so your team can run the system without vendor dependency.
Core deliverables usually include:
- Assessment & maturity baseline (delivery flow, bottlenecks, risk areas, cloud readiness)
- CI/CD pipeline implementation with testing and security gates
- Infrastructure as Code modules and environment provisioning
- Container/Kubernetes enablement (where it fits) with deployment standards
- DevSecOps automation (SAST/SCA, secrets, IaC scanning, container scanning)
- Observability & reliability practices (logs/metrics/traces, SLOs, dashboards)
- Governance & documentation (runbooks, RACI/ownership, evidence trails)
- Enablement (workshops, pairing, internal platform handover)
What separates strong providers from average ones is how well they connect these deliverables into a sequenced roadmap with measurable KPIs.

DevOps Assessment & Readiness Evaluation
This is where you find the real constraints: brittle legacy deploy logic, undocumented dependencies, inconsistent environments, and manual approvals that don’t map to actual risk.
A good assessment typically covers:
- Application topology (monolith vs services, coupling, runtime constraints)
- Current delivery workflow (handoffs, approvals, test coverage, release frequency)
- Infrastructure state (pets vs cattle, drift, provisioning lead time)
- Cloud readiness (networking, identity, landing zone requirements)
- Security posture (secrets handling, vulnerability scanning, access controls)
- Team maturity (ownership, incident response, release management)
Most importantly, the assessment produces a prioritized backlog so you don’t try to “fix everything” at once.
CI/CD Pipeline Design & Implementation
CI/CD reduces release risk by turning tribal knowledge into automated, repeatable steps. Done well, pipelines enforce consistent build, test, scan, and deployment workflows.
Implementation usually includes:
- Pipeline templates (“golden pipeline” patterns)
- Automated test stages (unit → integration → regression/performance where needed)
- Security gates (policy checks, scanning, signing)
- Deployment orchestration (progressive delivery, safe rollback paths)
- Environment promotions (dev → staging → prod with traceability)
The target is simple: smaller changes shipped more frequently, with guardrails.
Infrastructure as Code Implementation
IaC replaces manual configuration with versioned, reviewable infrastructure. This matters during cloud migration because “just click it in the console” doesn’t scale—and it creates drift.
Expect work such as:
- Terraform/CloudFormation modules for core infrastructure
- Versioned environments and reusable templates
- Drift detection and remediation workflows
- Standard naming/tagging conventions for cost and governance
You don’t need to IaC everything on day one, but you do need a plan for what becomes “code-owned.”
Cloud & Container DevOps Enablement
Cloud migration often introduces new operational complexity: networking, identity, managed services, containers, Kubernetes, and multi-environment sprawl.
Enablement focuses on:
- Cloud deployment standards (accounts/projects, VPC/VNet patterns, IAM)
- Containerization approach (if appropriate) and consistent runtime packaging
- Kubernetes delivery patterns (Helm/Kustomize, GitOps-friendly deployments)
- Build provenance and artifact repositories for traceable releases
The best outcome is consistent environments so bugs don’t hide in “it works on staging.”
DevSecOps & Security Automation
Security automation is how you avoid turning every release into a ticket queue. Shift-left controls help you find issues earlier—when they’re cheaper to fix and less disruptive.
Common inclusions:
- SAST (static analysis) and SCA (dependency scanning)
- Secrets scanning in code and pipelines
- IaC scanning for misconfigurations
- Container image scanning and signing
- Policy-as-code checks before deployment
This makes security a normal part of delivery, not an end-of-quarter event.
Monitoring, Observability & Reliability Engineering
Monitoring tells you something broke. Observability helps you find why it broke, across logs, metrics, and traces.
Implementation includes:
- Instrumentation standards and log/trace correlation
- Dashboards by service and user journey
- Alerting strategy (signal over noise)
- SLOs/SLIs and error budgets
- Incident workflows and runbooks
For legacy-to-cloud, this is often where teams see the fastest reliability improvement—because visibility was the missing foundation.
Ad-Hoc DevOps vs Proper DevOps Implementation
Teams often say “we’re doing DevOps” when they have a few scripts, a half-built pipeline, and one person who knows how deployments work. That’s ad-hoc. It might work—until you migrate to cloud, scale teams, or face compliance audits.
A structured approach aligns strategy, tooling, and operating model so improvements are repeatable across apps. When you invest in DevOps implementation services, you’re paying for that repeatability—templates, standards, documentation, and enablement—not just “automation.”
Here’s a practical comparison you can use in internal planning discussions:

Why DevOps Matters More During Legacy-to-Cloud Migration
Legacy-to-cloud migration increases delivery risk because you’re changing infrastructure, networking, identity, runtime behaviors, and sometimes architecture—all while the business still needs releases. This is where DevOps implementation services become a risk-control system: they standardize how changes move from commit to production, and they make failures easier to detect and recover from.
High-performing teams tend to ship more frequently with lower failure rates and faster recovery, as captured in DORA’s delivery performance metrics. Reliability practices like SLOs and error budgets are core SRE concepts used to align engineering effort to user experience.
Cloud migration without DevOps often looks like this: you move workloads, then discover you can’t reproduce environments, can’t observe systems, can’t rollback safely, and can’t meet audit requirements. DevOps-first flips the sequence so migration is safer.
Common Legacy Pain Points DevOps Fixes
Most legacy delivery pain is not “old code.” It’s invisible dependencies and manual process.
DevOps addresses common issues like:
- Manual release gates driven by fear rather than measurable risk
- Shared environments that block parallel work and cause conflicts
- Brittle deployments where one missed step breaks production
- Unclear ownership (“ask Ops” / “ask Dev” loops)
- Slow rollback because releases aren’t packaged or versioned consistently
- Inconsistent testing and flaky staging environments
- Poor monitoring that detects failures too late
- Hidden infrastructure dependencies (hardcoded IPs, legacy DNS, batch jobs)
When these issues persist into the cloud, they usually get worse—not better—because the platform surface area expands.
What Good Looks Like After DevOps Implementation
“Good” isn’t a specific toolchain. It’s measurable outcomes that you can track and defend in leadership reviews.
After implementation, you should expect:
- Higher deployment frequency without increasing production incidents
- Reduced lead time for changes (commit to production)
- Lower change failure rate (fewer rollbacks/hotfixes)
- Faster MTTR with clear incident ownership and runbooks
- Defined SLOs for critical services and user journeys
- Better audit posture via deployment traceability and access logs
These map directly to DORA metrics and SRE reliability practices.
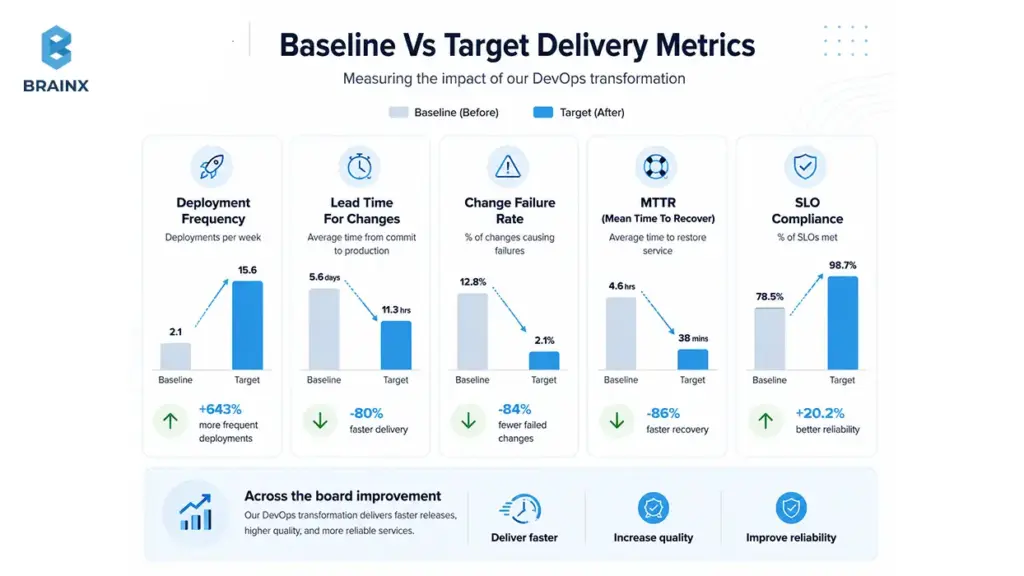
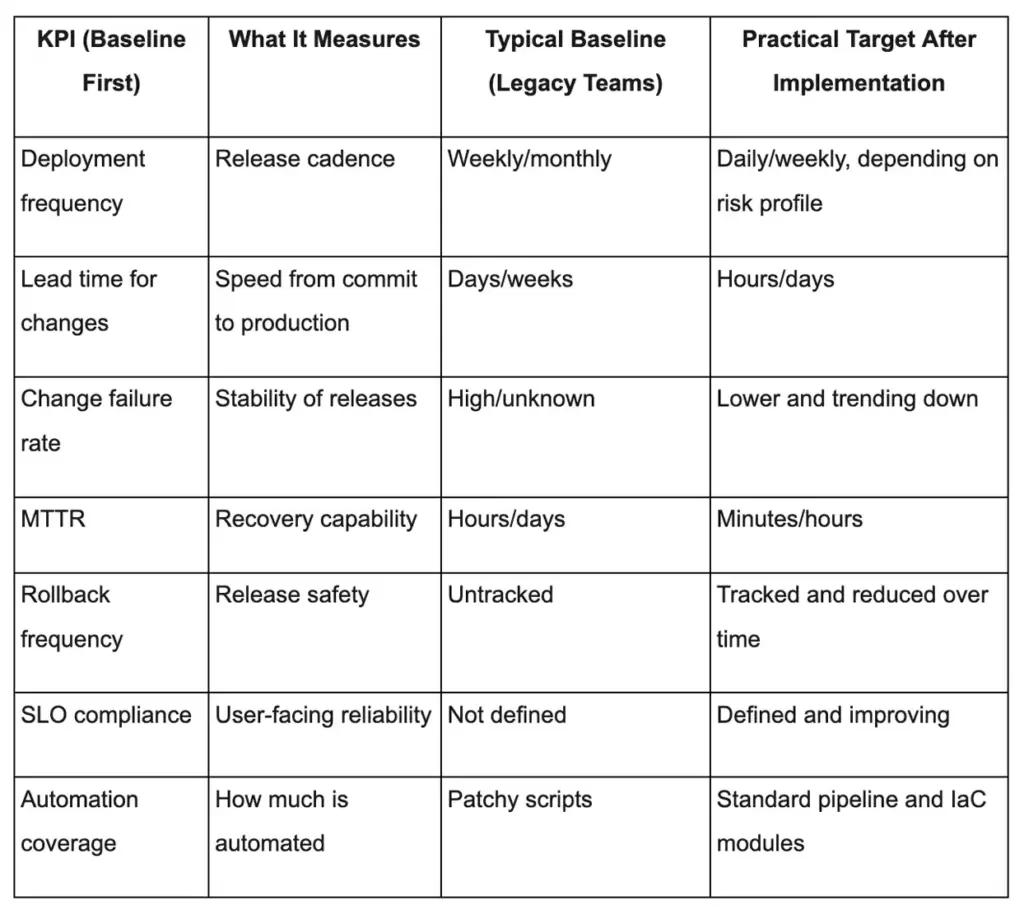
DevOps KPI Baseline and Target Outcomes
Before you start, baseline where you are. Without a baseline, you can’t prove ROI, and you can’t prioritize the right automation.
Why DevOps Implementations Fail Without Expert Guidance
Most failures aren’t because DevOps “doesn’t work.” They happen because teams underestimate sequencing, adoption, and legacy constraints. That’s why DevOps consulting & implementation services are often worth it: they bring a proven framework and reduce rework.
Common failure patterns show up across industries:
- Tool adoption without workflow redesign
- Partial automation that shifts bottlenecks instead of removing them
- Compliance surprises after pipelines are already built
- Monitoring that generates noise without ownership and runbooks
- Migration projects that ignore legacy database realities
If you want to avoid “we tried DevOps and it didn’t stick,” you need to treat it like a product: roadmap, stakeholders, metrics, and iteration.

Tool-First, Strategy-Last Approach
Buying tools feels like progress because it’s visible. But tools don’t resolve ambiguity about ownership, release policy, or environment strategy.
A strategy-first approach defines:
- What you’re standardizing (pipelines, environments, evidence)
- What you’re optimizing for (speed, risk reduction, compliance, cost)
- Where you’ll start (pilot selection and rollout plan)
Then tools follow those decisions.
Lack of CI/CD & Automation Maturity
If your pipeline automates builds but deployments remain manual, you still have the riskiest steps performed under pressure. Partial automation also tends to create “pipeline theater”—green builds that don’t reflect production readiness.
Maturity means automating the end-to-end path, including:
- Tests that reflect real integration risk
- Deployment verification checks
- Rollback criteria and automation hooks
Security Bolted On Too Late
Late security reviews are a leading cause of release delays and surprise rework. In cloud migration, it’s worse because identity and network changes affect everything.
Shift-left security introduces early checks so teams get fast feedback while changes are small and fixable.
Poor Collaboration Between Dev & Ops
Silos create handoffs. Handoffs create queues. Queues create slow releases and blame cycles.
Healthy collaboration looks like:
- Shared on-call rotations (or at least shared incident ownership)
- Joint release planning and postmortems
- Clear “you build it, you run it” boundaries by service
No Metrics or Feedback Loops
If you can’t measure lead time, failure rate, or MTTR, you can’t know whether automation is helping. Teams then optimize the wrong thing—like building more dashboards instead of reducing noisy alerts.
Metrics should drive a monthly improvement loop: measure → identify bottleneck → fix → re-measure.
Underestimating Legacy System Complexity
Legacy systems aren’t only old code. They include:
- Shared databases and tight coupling
- Batch jobs and cron-based workflows
- Undocumented deployment scripts
- Hardcoded infrastructure assumptions
- Vendor-supported components with strict constraints
Your roadmap must account for these realities, especially database and integration points.
Weak Change Management and Internal Adoption
A perfect pipeline that nobody uses is still a failure.
Adoption requires training, documentation, migration playbooks, and a phased rollout so teams can learn without risking production.
Poor Documentation and Handover
Without runbooks and architecture notes, organizations become dependent on a few individuals—or a vendor.
Documentation should be a deliverable: pipeline docs, IaC module usage guides, incident runbooks, and an ownership map.
Steps to Consider for Successful DevOps Implementation
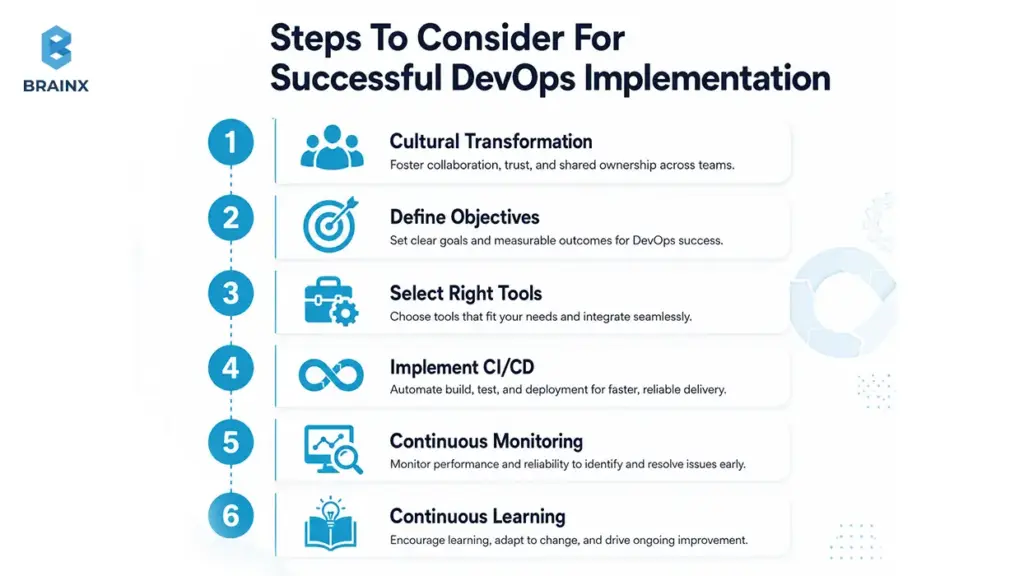
Before you jump into phases and tooling, align on a few preconditions. This checklist prevents common “restart” moments mid-project.
Step 1. Cultural Transformation
DevOps requires shared responsibility for delivery and reliability. That doesn’t mean everyone does everything—it means teams collaborate around outcomes.
Start by agreeing on:
- Who owns production health by service
- How incidents are handled (no-blame, learning-focused)
- What “done” means (tests, security checks, observability)
Step 2. Define Objectives
Tie DevOps work to business outcomes so prioritization becomes easy.
Examples:
- Reduce release cycle from monthly to weekly
- Cut MTTR from hours to under one hour
- Improve audit readiness with automated evidence collection
- Reduce cloud spend variance with consistent tagging and visibility
Step 3. Select Right Tools
Tool selection should follow architecture and maturity.
Decide first:
- Cloud provider and account/project strategy
- Container/Kubernetes needs (or not)
- Compliance requirements (SOC 2, HIPAA, PCI DSS)
- Team skill level and preferred workflows
Then choose tools that fit—not tools that require your team to change everything at once.
Step 4. Implement CI/CD
Focus on a reliable “golden path” for delivery:
- Build → test → scan → package → deploy → verify
- Start with a pilot app and a single pipeline template
- Add progressive delivery where risk warrants it (canary/blue-green)
Step 5. Continuous Monitoring
Instrument early so migration doesn’t blind you.
At minimum:
- Centralized logs, metrics, traces
- Dashboards for critical paths
- Alerts tied to user impact
- A clear on-call and escalation workflow
Step 6. Continuous Learning
DevOps isn’t a one-time project; it’s an improvement loop.
Build routines like:
- Sprint retrospectives that include release/incident insights
- Postmortems with action items and owners
- Living documentation that’s updated as systems change
The Step-by-Step DevOps Implementation Roadmap
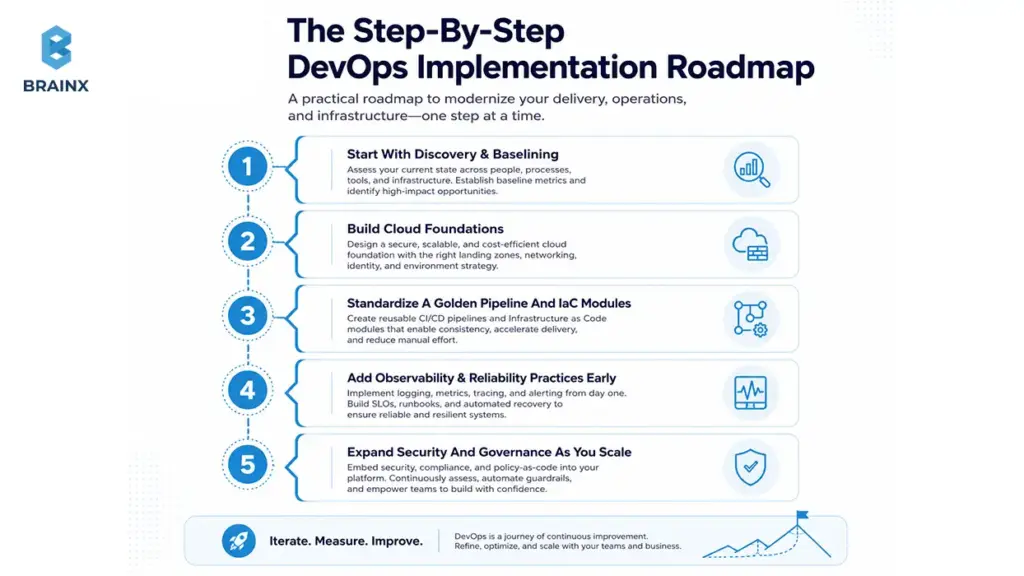
A DevOps roadmap is a sequencing plan: what to implement first, what depends on what, and how to roll changes across teams and apps without breaking production.
Most organizations succeed when they treat the program like a rollout of an internal product:
- Start with discovery and baselining
- Build cloud foundations before scaling pipelines
- Standardize a golden pipeline and IaC modules
- Add observability and reliability practices early
- Expand security and governance as you scale
This section introduces the journey; the next section breaks it into six phases you can follow.
Typical Timeline by Company Stage
The timeline depends less on company size and more on legacy complexity and compliance needs. Still, these ranges help set expectations:
- Startup (1–3 product teams): 6–10 weeks to establish strong CI/CD + IaC baseline; 3–6 months to mature reliability/security.
- Scale-up (multiple services, growing team): 8–16 weeks for standardization and rollout; 4–9 months for multi-team adoption and governance.
- Mid-market (mixed legacy + cloud): 3–6 months for phased rollout across key apps; 6–12 months for broad maturity.
- Enterprise (many apps, strict controls): 6–12 months in waves; continuous improvement thereafter.
The key is to avoid boiling the ocean: pick a pilot, prove the pattern, then scale.
What the First 90 Days Usually Look Like
A buyer-friendly way to plan is to map the first 90 days into outcomes. This is a common structure for a DevOps implementation plan that still leaves room for your constraints.
Days 1–30 (Discovery + Pilot Definition)
- Stakeholder interviews and workflow mapping
- Assessment and KPI baseline
- Pilot app selection and success criteria
- Cloud foundation planning (landing zone requirements)
Days 31–60 (Foundation + Pilot Build)
- Cloud landing zone setup (networking, IAM, guardrails)
- CI/CD pilot (build/test/scan/deploy)
- IaC modules for environments
- Initial monitoring dashboards and alerting
Days 61–90 (Rollout + Governance + Handover)
- Expand pipelines to additional apps/services
- Governance model and release policies
- Runbooks, incident workflow, ownership/RACI
- Handover and enablement sessions for internal teams
The 6 Phases of DevOps Implementation From Legacy to Cloud
This phased model is designed for legacy-to-cloud transformations where you must modernize delivery without destabilizing production. You can run phases in overlap, but the dependencies matter: foundations before scale, observability before heavy migration, and governance before multi-team rollout.
Use this as a reference model and adapt it to your risk profile, compliance needs, and workload mix.
Phase 1: Discovery, Assessment & DevOps Maturity Baseline
Phase 1 produces clarity: where you are today, what’s constraining you, and what success will look like in measurable terms.
A strong discovery phase prevents expensive rework later, especially when legacy systems hide dependencies across databases, batch jobs, and network rules.

What to Assess Before DevOps Implementation
Assess across delivery, infrastructure, security, and teams:
- Application portfolio (criticality, change rate, failure impact)
- Current build/test/deploy flow and manual gates
- Environments (how they’re created, how often they drift)
- Access and identity (who can deploy, who can change infra)
- Security gaps (secrets, scanning coverage, patching approach)
- Monitoring maturity (what’s measured, what’s missing)
- Team topology and ownership (who is responsible for what)
Document findings in a format leadership can act on: bottlenecks, risks, and a prioritized backlog.
Mapping Legacy Dependencies
Legacy systems often fail in the cloud because dependencies were never mapped explicitly.
Map:
- Monolith boundaries and internal modules
- Shared databases and schema ownership
- Batch jobs (cron, ETL, nightly processing)
- Third-party integrations (payment gateways, ERP, identity providers)
- Old deployment scripts and manual steps
- Approval points and who controls them
This dependency map becomes the backbone of your rollout plan.
Choosing the Right Migration Path for Each Workload
Not every workload should be refactored. Some should be rehosted first to reduce time-to-value, then improved later.
Common migration paths include: rehost, replatform, refactor, retire, retain.
A practical decision approach:
- Rehost when speed matters and risk is manageable
- Replatform when small changes unlock big operational wins
- Refactor when scalability, maintainability, or cloud-native benefits are required
- Retire when the system no longer delivers value
- Retain when constraints (vendor, compliance, latency) block migration
Your DevOps roadmap should support multiple paths simultaneously.
Outputs From the Discovery Phase
Expect tangible outputs you can use immediately:
- Target architecture (cloud + delivery + observability)
- DevOps backlog with priority and dependencies
- Risk register (delivery, security, reliability)
- KPI baseline and measurement method
- Pilot workload selection and success criteria
- Migration path per workload
- Toolchain recommendation aligned to constraints
- Security gap analysis and remediation plan
Phase 2: Cloud Foundations, Landing Zone, Identity & Governance
Before you scale pipelines, you need a secure, consistent cloud foundation. Otherwise, every new app becomes a custom setup with inconsistent controls.
This phase sets up the cloud landing zone: networking, identity, accounts/projects, guardrails, and baseline monitoring/logging.
Network, Account Structure and IAM Patterns
Key decisions include:
- Account/subscription/project strategy (by environment, by team, by business unit)
- Network segmentation (prod vs non-prod, shared services, private connectivity)
- IAM patterns (roles, groups, service accounts, workload identity)
Get these wrong and you’ll spend months undoing permissions and network rules.
Policy-as-Code and Guardrails
Guardrails should be automated so they don’t slow teams down.
Examples:
- Prevent public storage buckets by default
- Require encryption at rest and in transit
- Enforce tagging for cost and ownership
- Limit who can create high-cost resources
Policy-as-code gives you consistent enforcement with auditability.
FinOps Basics for Early Cost Visibility
Cloud costs become a problem when they’re discovered too late.
Build early visibility with:
- Tagging standards (app, env, owner, cost center)
- Budget alerts and anomaly detection
- Showback dashboards for teams
Security as a Cross-Cutting Layer From Day One
Security isn’t a final phase—it’s embedded across the roadmap.
Shift-left practices include:
- Identity and least privilege early
- Secrets management standards
- Central logging and security telemetry
Phase 3: CI/CD & Build/Release Standardization
This phase is where delivery becomes consistent and scalable. You implement a “golden pipeline” approach: a reusable pipeline pattern that teams adopt with minimal customization.
In many organizations, this is the first moment where stakeholders feel the impact—because releases stop being bespoke events. This is also where DevOps implementation services often deliver the fastest measurable results through reduced lead time and fewer release failures.
Source Control, Branching and Release Workflow
Choose a workflow that matches team size and release risk:
- Trunk-based development: fast feedback, smaller changes, fewer merge headaches
- GitFlow-style branching: clearer release branches but can slow integration
The best answer is usually the one your teams can adopt consistently. Standardization beats theoretical perfection.
Automated Testing Strategy
Pipelines should reflect real risk, not just “run unit tests.”
Common gates include:
- Unit tests for fast feedback
- Integration tests for service boundaries
- Contract tests to stabilize APIs
- Regression tests for critical workflows
- Performance tests for scale-sensitive systems
- Security tests integrated into CI
Start with the highest-value tests that catch the most expensive failures.
Database Change Management for Legacy Systems
Databases are where legacy migrations often fail. Schema changes, data migrations, and backward compatibility require discipline.
Include:
- Versioned migrations (e.g., Flyway/Liquibase patterns)
- Backward-compatible schema rollout strategy
- Automated checks for migration safety
- Clear rollback strategy (or forward-fix policy when rollback is unsafe)
Release Strategies for Legacy Apps
Safer releases reduce business risk during migration:
- Blue/green to switch traffic between environments
- Canary to test with a small user percentage
- Feature flags to decouple deploy from release
- Phased rollout by region/customer segment
- Clear rollback criteria and automated verification
For legacy apps that can’t support progressive delivery, focus on packaging, versioning, and deterministic deployments first.
Phase 4: Infrastructure as Code & Environment Automation
Phase 4 removes “environment snowflakes.” Your environments become reproducible and reviewable—critical for scaling cloud migration.
Standard Modules and Reusable Templates
Reusable modules reduce setup time and improve consistency across teams.
Typical modules include:
- Networking baselines and security groups
- Compute templates (VMs, autoscaling groups, container services)
- Databases and caches with standard backups/encryption
- Logging/monitoring integration by default
Version modules like software so teams can upgrade safely.
Secrets Management and Configuration Strategy
Secrets are one of the most common sources of cloud incidents and security findings.
Standardize:
- A secrets manager (cloud-native or dedicated)
- How secrets are injected into apps (not stored in repos)
- Rotation policies and break-glass access
- Config separation by environment
This reduces leakage risk and stabilizes deployments.
Environment Provisioning and Drift Control
Environment drift creates “works in staging” failures.
Controls include:
- Automated environment provisioning from code
- Drift detection in CI
- Controlled manual changes (or none) with audit logs
- Periodic reconciliation and cleanup
With drift under control, cloud migration becomes less about firefighting and more about predictable rollout.
Phase 5: Observability, Reliability Engineering & Incident Response
Cloud migration can increase operational noise if you don’t implement observability with intent. Phase 5 makes reliability measurable and improves recovery when failures occur.
This is where SRE practices matter: define SLOs, measure SLIs, and make incident response a practiced workflow.
Defining SLOs and SLIs for Legacy and Cloud Services
Start with user-facing outcomes:
- Availability of checkout/login/search
- Latency for critical endpoints
- Error rate thresholds tied to user impact
Define SLIs (what you measure) and SLOs (your target). Then build alerting around SLO burn, not raw CPU spikes.
Incident Management Workflow
An incident process reduces MTTR more than any single tool.
Include:
- Severity levels and triage criteria
- On-call schedules and escalation
- Runbooks for top failure modes
- Postmortems with action items and owners
- Ownership mapping per service/component
The result is faster diagnosis, clearer accountability, and fewer repeat incidents.
Performance Testing and Capacity Planning in Cloud
Capacity planning changes in cloud: scaling is easier, but misconfiguration can be costly.
Implement:
- Load/performance testing in pre-prod for critical services
- Autoscaling policies and limits
- Cost-aware capacity decisions (right-sizing, reserved capacity where relevant)
This prevents migration from simply moving legacy inefficiency into a more expensive environment.
Phase 6: DevSecOps, Compliance & Continuous Governance
Phase 6 ensures security and compliance controls are built into delivery so speed doesn’t degrade as requirements grow.
You embed gates and evidence collection directly in pipelines and cloud governance.
Shift-Left Security in CI/CD
Shift-left controls commonly include:
- SAST for code vulnerabilities
- SCA for dependency risk and license issues
- IaC scanning for cloud misconfigurations
- Container scanning for image vulnerabilities
- Secret detection to prevent leaks
The key is fast feedback with clear remediation guidance—otherwise developers bypass controls.
Compliance Controls by Industry Need
Compliance should map to business context:
- SaaS: SOC 2 / ISO 27001 controls like access logging, change management, evidence trails
- Healthcare: HIPAA-driven access controls, auditability, encryption, and monitoring
- Payments/eCommerce: PCI DSS requirements for segmentation, logging, vulnerability management
- Enterprise software: audit logs, access reviews, change approvals, and traceability
This avoids implementing heavyweight controls where they aren’t required.
Auditability and Evidence Collection Automation
Audits become easier when evidence is generated continuously:
- Deployment history and approvals (where required)
- Access logs and role changes
- Artifact provenance (what code is running)
- Policy evaluation results and exceptions
Automate evidence capture so audits don’t pause engineering.
Access Reviews, Least Privilege and Supply Chain Security
Identity governance and supply chain risk are now board-level concerns.
Include:
- Periodic access reviews and least-privilege enforcement
- Signing artifacts and verifying provenance
- Dependency policies for critical systems
- Controls for CI/CD runner security and credentials

Tools & Stack Selection: What to Standardize vs Keep Flexible
Tool selection should enable a consistent delivery system without locking you into unnecessary complexity. The right framework is to standardize what must be consistent (pipelines, identity, observability) and keep flexibility where teams benefit (frameworks, some testing choices).
Standardize:
- Source control and artifact repositories
- CI/CD pipeline templates and gating approach
- IaC approach and module standards
- Secrets management and identity patterns
- Observability stack and alerting conventions
Keep flexible (within guardrails):
- App frameworks and runtime choices
- Team-level test tooling (as long as results integrate into pipelines)
- Deployment strategy variations by workload risk
Reference Stack Examples by Company Stage
These are examples to illustrate maturity levels—not prescriptions.
- Startup stack: GitHub/GitLab, managed CI, Terraform, cloud-native monitoring, basic SAST/SCA
- Scale-up stack: golden pipelines, IaC modules, centralized logging/metrics/tracing, container registry, secrets manager, progressive delivery tooling
- Enterprise stack: policy-as-code, multi-account governance, advanced SIEM integrations, compliance evidence automation, standardized internal developer platform patterns
Choose the simplest stack that meets your reliability and compliance needs.
Avoiding Tool Sprawl
Tool sprawl happens when every team chooses a different solution and no one owns the platform roadmap.
Avoid it by:
- Defining a platform owner (platform team or enablement lead)
- Creating a standards catalog (approved tools + patterns)
- Running quarterly platform reviews (what to adopt, retire, consolidate)
- Measuring adoption and outcomes (not number of tools)
Team Structure & Operating Model So DevOps Sticks
Tools don’t create DevOps outcomes—teams do. If your operating model doesn’t define ownership, on-call, and standards, the implementation will decay over time.
A sustainable model clarifies:
- Who owns the pipeline templates and IaC modules
- Who owns production health by service
- How teams request platform changes
- How incidents and postmortems are run
- How documentation stays current
Platform Engineering vs a Traditional DevOps Team
A traditional “DevOps team” often becomes a bottleneck: they build pipelines, manage infra, and get paged for everything.
Platform engineering shifts the model:
- Platform team builds self-service tooling and golden paths
- Product teams own delivery and reliability using those paths
- Governance and security are built into the platform
This scales better and reduces dependency on a single team.
Skills Matrix for DevOps Implementation
A practical skills map helps you staff correctly:
- Cloud architecture (networking, IAM, managed services)
- CI/CD engineering (pipelines, artifact management, release automation)
- IaC and automation (Terraform/modules, drift control)
- Security engineering (DevSecOps tooling, policies, threat modeling basics)
- SRE practices (SLOs, alerting, incident response)
- QA automation (test strategy, reliability in CI)
- Release management (progressive delivery, rollback planning)
If these skills are scattered across a few people, external support can stabilize delivery while you upskill internally.
Change Management and Enablement Plan
Adoption is a deliverable. An enablement plan typically includes:
- Workshops per team (pipelines, IaC usage, incident response)
- Pairing sessions during early rollouts
- Onboarding docs and runbooks
- “Office hours” for platform questions
- A clear handover milestone with ownership transfer
Without enablement, the program becomes “that vendor thing” instead of your new normal.
Real-World DevOps Implementation Use Cases
Use cases are where DevOps becomes concrete. The value shows up in fewer failed releases, faster recovery, and smoother cloud migration—not just prettier pipelines.
Below are common scenarios where implementation work produces measurable outcomes.
Legacy Application Modernization
Modernization often starts with stabilizing delivery. You don’t need to refactor everything to get value.
Common patterns:
- Wrap legacy apps with repeatable build/deploy pipelines
- Containerize selectively where it reduces environment drift
- Use IaC to standardize infrastructure even if the app remains monolithic
- Add observability before major migration waves
This reduces the risk of making changes to a system you don’t fully control.
Faster Software Release Cycles
If releases are slow, it’s usually due to manual steps and long verification cycles.
Implementation helps by:
- Automating test execution and reporting
- Standardizing pipeline gates
- Adding progressive delivery strategies where possible
- Reducing handoffs with clearer ownership
Teams can then ship smaller changes more frequently—usually with fewer production surprises.
Cloud Migration and Environment Standardization
Migration efforts often fail when environments differ across dev/staging/prod.
DevOps reduces drift by:
- Creating reproducible environments with IaC
- Standardizing identity, secrets, and deployment patterns
- Establishing a landing zone and shared guardrails
The result: fewer “it only breaks in prod” incidents during migration.
Security and Compliance Automation
For regulated teams, manual audits and approvals can crush delivery speed.
DevSecOps automation:
- Adds security checks into CI/CD
- Generates audit evidence continuously
- Enforces policy-as-code guardrails in cloud
You reduce audit scramble and avoid last-minute compliance rework.
Reliability Improvement for Production Systems
Reliability improvements are often the fastest ROI in cloud transitions.
Implementation adds:
- SLOs and user-journey dashboards
- Better alerting signals (less noise)
- Clear incident workflows and runbooks
- Postmortems that prevent repeat failures
This directly impacts customer experience and support cost.
Cost, Timeline & Engagement Models for DevOps Implementation Services
Buyers usually need clarity on scope and cost drivers before they can engage. Pricing varies widely because DevOps work depends on legacy complexity and compliance constraints, but you can still model ranges and decisions.
A good provider will give a phased plan with milestones so you can fund the program incrementally and see value early. If you’re evaluating DevOps implementation services, ask for pricing tied to deliverables—assessment outputs, pilot pipeline, IaC modules, observability baseline, and handover.
What Drives DevOps Implementation Cost
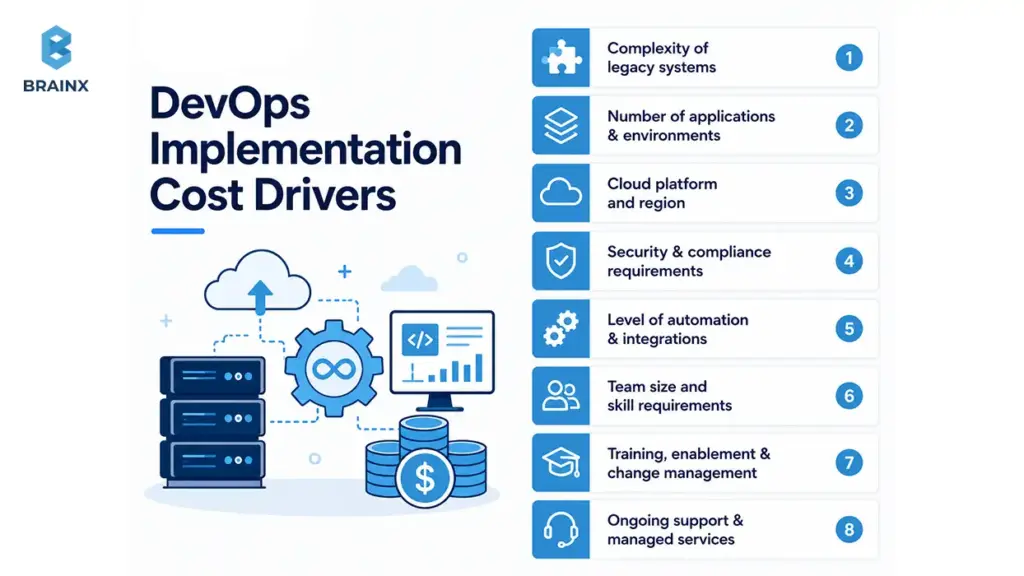
Primary cost variables include:
- Legacy complexity (monoliths, shared DBs, batch jobs)
- Compliance requirements and audit evidence needs
- Cloud provider and landing zone complexity
- Number of applications and deployment patterns
- Existing toolchain maturity (starting from zero vs optimizing)
- Depth of automation (CI only vs CI+CD+IaC+policy-as-code)
- Team size and number of squads to enable
- Support needs post-implementation (hypercare or managed ops)
If you want lower cost, limit scope to a pilot plus reusable foundations that you can scale internally.
Typical Phase and Duration Ranges
Planning ranges (varies by complexity):
- Pilot (1–2 apps): 4–8 weeks
- Production rollout (5–15 apps): 8–16 weeks
- Enterprise-wide rollout (many apps/teams): 4–12 months in waves
The best plans don’t promise “full transformation” in a few weeks—they show how value arrives early and compounds over time.
Engagement Options
Common engagement models include:
- Advisory-only (assessment + roadmap)
- Implementation project (build and handover)
- Hybrid (advisory + implementation + enablement)
- Managed DevOps (ongoing operations and platform support)
Many teams choose DevOps consulting & implementation services for the first 8–16 weeks, then transition either to internal ownership or a managed model for stability during migration waves.
Key Challenges of DevOps Implementation

DevOps adoption isn’t blocked by technology alone. It’s blocked by incentives, legacy constraints, and competing priorities.
Knowing the common challenges helps you design mitigations into the roadmap rather than reacting mid-project.
Resistance and Reluctance
Automation changes workflows and accountability. People may fear loss of control or increased on-call burden.
Mitigate with:
- Clear ownership boundaries
- Training and pairing
- Early wins via a pilot team
- Leadership support for standardized practices
Complexity of Tools
Too many tools—or the wrong ones—create cognitive load.
Mitigate by:
- Standardizing a small core stack
- Providing templates and golden paths
- Documenting “how we do delivery here”
Organizational Barriers
Silos and approval bottlenecks slow everything.
Mitigate with:
- RACI and ownership mapping
- Streamlined change control tied to risk level
- Shared incident response workflows
Automation-related Issues
Partial automation creates brittle scripts and inconsistent pipelines.
Mitigate with:
- Pipeline templates
- Infrastructure modules
- Versioning and testing for automation code
Shortage of Skillsets or Resources
DevOps needs a blend of cloud, automation, security, QA, and reliability skills.
Mitigate by:
- Upskilling plan and enablement
- Short-term expert support during foundations
- Hiring strategy aligned to platform ownership
Legacy System Dependencies
Shared databases and unsupported tools can block modernization.
Mitigate by:
- Dependency mapping early
- Choosing migration paths per workload
- Stabilizing delivery before deep refactoring
Security and Compliance Gaps
If planned late, security requirements can force redesign.
Mitigate by:
- Shift-left controls in CI/CD
- Policy-as-code guardrails
- Early involvement of security stakeholders
Poor Documentation and Knowledge Transfer
Without documentation, teams can’t scale adoption.
Mitigate by:
- Making docs/runbooks a deliverable
- Holding handover sessions
- Creating an internal portal for platform usage
Measuring the Success of Your DevOps Implementation
If you can’t measure it, you can’t improve it—or justify further investment. Success measurement should include delivery performance and reliability outcomes, mapped to business impact.
DORA metrics are widely used for delivery performance tracking.
Key Performance Indicators to Track
Track these before and after implementation:
- Deployment frequency
- Lead time for changes
- Change failure rate
- MTTR (mean time to restore)
- Rollback frequency
- Failed deployment rate
- SLO compliance (per critical service/journey)
- Automation coverage (pipelines, IaC, policy checks)
- Incident volume and alert quality (signal-to-noise)
Avoid vanity metrics like “number of tools adopted.” Focus on outcomes.
Linking DevOps Metrics to Business Outcomes
Executives care about customer impact and cost. Translate metrics into business language:
- Faster time to market → quicker revenue realization
- Reduced downtime → higher retention and fewer support escalations
- Lower operational cost → less manual toil and fewer emergency fixes
- Better customer experience → improved NPS/CSAT and conversion
- Better audit readiness → reduced compliance overhead and risk
- Stronger scalability → confidence during peak load and expansion
A metrics-to-outcome map also helps prioritize what to automate next.
DIY DevOps vs Professional DevOps Implementation
DIY can work for small teams with strong in-house platform skills and a narrow scope. But for legacy-to-cloud programs, the cost of mis-sequencing is high: rework, outages, and stalled migrations.
A professional approach brings reusable frameworks, proven patterns, and faster time-to-stable outcomes. This is where DevOps consulting & implementation services often pay for themselves: fewer false starts and stronger handover artifacts.
Who Should Invest in DevOps Implementation Services?
Not every team needs a full transformation program. But many organizations benefit from DevOps implementation services when delivery and operations are blocking business goals.
These are the strongest fit profiles.
Companies Moving Legacy Systems to Cloud
If you’re migrating and still releasing, you need a delivery system that reduces risk as infrastructure changes.
DevOps provides:
- Standard environments
- Safer release patterns
- Better visibility during migration waves
Teams With Slow or Risky Release Cycles
If releases require heroics, you’re paying an ongoing tax.
Implementation helps:
- Reduce manual gates
- Automate verification
- Improve rollback and recovery
Businesses Scaling Product Engineering Teams
As teams grow, inconsistency becomes expensive.
Standardization through pipelines, IaC modules, and operating model prevents every squad from reinventing delivery.
Companies With Security or Compliance Pressure
If audits are painful, automate evidence and controls.
DevSecOps practices reduce last-minute compliance work and keep releases moving.
Organizations With Unclear Infrastructure Ownership
If nobody owns environments end-to-end, incidents take longer and changes become riskier.
A clear RACI plus platform ownership model fixes that ambiguity.
How to Choose the Right DevOps Implementation Partner
Choosing a partner is less about brand names and more about fit: can they operate in your constraints, deliver reusable foundations, and leave your team stronger?
When evaluating DevOps implementation services provider companies, prioritize providers that can show measurable outcomes, clear deliverables, and a strong handover culture—not just tool certifications.
Evaluation Criteria
Use this checklist to evaluate capability:
- Proven cloud experience (landing zones, IAM, governance)
- CI/CD maturity (golden pipelines, progressive delivery, rollback thinking)
- Security capability (DevSecOps tooling, policy-as-code, evidence automation)
- Documentation standards (runbooks, ownership maps, module guides)
- Reliability practices (SLOs, alerting strategy, incident workflows)
- References and relevant case studies (legacy + cloud contexts)
- Handover approach (enablement, pairing, internal ownership transfer)
Ask for examples of deliverables, not just slides.
Questions to Ask During RFPs or Interviews
Practical questions that expose real competence:
- How do you baseline DORA metrics and define targets for our context?
- What does your first 30/60/90-day plan look like for a pilot + rollout?
- How do you handle legacy database migrations and rollback constraints?
- What controls do you implement for IAM, secrets, and CI/CD credentials?
- What documentation do we get at handover—runbooks, diagrams, module guides?
- How do you prevent tool sprawl and ensure teams adopt the golden path?
The quality of answers matters more than tool names.
Red Flags to Watch For
Avoid partners who:
- Push a preferred toolchain without understanding constraints (tool bias)
- Don’t propose a KPI baseline and measurement plan
- Ignore rollback and verification strategy
- Treat security as a final step
- Don’t commit to documentation as a deliverable
- Have no enablement plan for internal teams
A good partner should be comfortable saying “not yet” to tools that don’t fit your maturity.
The Future of DevOps: Emerging Trends
DevOps is increasingly shaped by security demands, platform engineering, and AI-assisted operations. These trends matter because they influence what you should design for now (standards, auditability, telemetry) even if you adopt capabilities later.
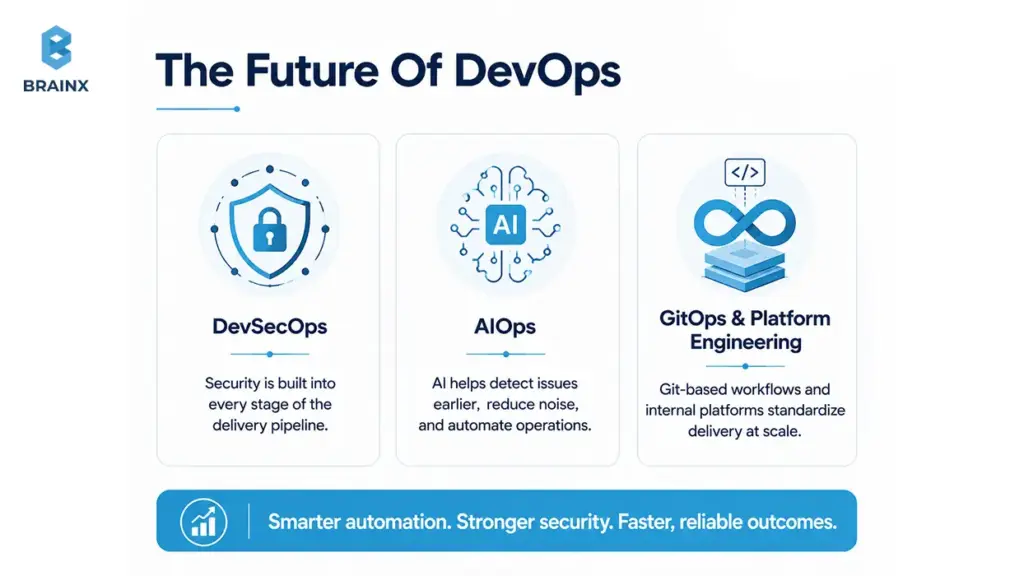
DevSecOps: Integrating Security Seamlessly
Security is moving from periodic review to continuous control.
Trends include:
- More policy-as-code enforcement
- Artifact signing and provenance verification
- Security telemetry integrated with CI/CD outcomes
Teams that bake this in early avoid painful retrofits later.
AIOps: Leveraging AI for Operations
AIOps uses AI to reduce operational burden by:
- Correlating alerts into incidents
- Detecting anomalies before users report them
- Suggesting likely root causes based on patterns
- Assisting incident triage and routing
Adoption works best when your observability data is clean and your incident taxonomy is consistent—another reason to invest in Phase 5 properly.
GitOps and Platform Engineering
GitOps brings a consistent “desired state” model to infrastructure and deployments: changes are made through pull requests, reviewed, and reconciled automatically.
Paired with platform engineering, GitOps helps organizations:
- Standardize delivery at scale
- Improve auditability through PR history
- Reduce configuration drift across environments
It’s especially valuable in multi-team cloud environments where manual changes become a governance nightmare.
How BrainX Helps With DevOps Implementation Services
BrainX Technologies supports organizations that need practical delivery outcomes during legacy modernization and cloud migration—without creating long-term dependency. Our engagements are structured to deliver reusable foundations (pipelines, IaC, observability, security automation) plus documentation and enablement so your team can own the system.
If you’re looking for DevOps implementation services with clear milestones and measurable KPIs, BrainX typically engages with a roadmap-first approach and then executes in phases. We also offer DevOps consulting & implementation services for teams that want advisory plus hands-on build work.
Delivery Approach: Assess, Pilot, Scale
Our delivery model is designed to reduce risk and show value early:
- Assess: current-state mapping, KPI baseline, dependency analysis, and roadmap
- Pilot: implement golden pipeline + IaC modules + initial observability on a pilot workload
- Scale: roll out standards across more apps/teams, add governance, and complete handover
This sequencing is especially effective for legacy-to-cloud programs where production stability is non-negotiable.
What You Get
Deliverables are explicit, so you can track progress and plan internal adoption:
- Assessment report and maturity baseline
- Phased roadmap and prioritized backlog
- CI/CD pipeline setup (golden pipeline templates)
- IaC templates/modules and environment automation
- Monitoring dashboards, alerting strategy, and SLO drafts
- Runbooks and incident response workflow
- Documentation and architecture diagrams
- Enablement sessions for developers and operators
You’ll know what “done” looks like at each milestone.
First 2 Weeks: What Kickoff Looks Like
To reduce uncertainty, kickoff is structured and lightweight:
- Access review (repos, CI, cloud accounts, monitoring tools)
- Current-state assessment and workflow mapping
- Stakeholder interviews (engineering, ops, security, product)
- Pilot workload selection and success criteria
- KPI baseline definition (how you’ll measure improvements)
- Roadmap draft with phase sequencing and dependencies
By the end of two weeks, you typically have clarity on scope, risks, and the fastest path to a production-grade pilot.
Conclusion
Legacy-to-cloud migration is hard because you’re changing platforms while the business still needs reliable delivery. A phased DevOps roadmap reduces that risk by standardizing pipelines, automating environments, embedding security early, and making reliability measurable.
If you’re planning modernization and want a roadmap that’s grounded in real-world constraints—legacy dependencies, database change management, governance, and incident readiness—start by validating your first 90 days and KPI baseline.
FAQ Section
What are DevOps implementation services, and what do they include?
DevOps implementation services cover the work needed to make software delivery repeatable, secure, and measurable. They usually include assessment, CI/CD pipelines, Infrastructure as Code, cloud foundations, observability, DevSecOps controls, documentation, and team enablement so internal teams can manage delivery with less risk..
How long does a legacy-to-cloud DevOps implementation take?
A focused pilot can show progress in 6–12 weeks, while a broader rollout across multiple apps often takes 3–6 months. Enterprise programs may take 6–12 months in phases, especially when compliance, identity, governance, and legacy dependencies are involved.
How much do DevOps implementation services cost?
Cost depends on legacy complexity, number of applications, cloud foundation scope, compliance needs, automation depth, and support requirements. A pilot with reusable CI/CD and IaC foundations costs less than an enterprise-wide rollout with advanced governance, evidence automation, and multi-team enablement.
What’s the difference between DevOps consulting & implementation services and managed DevOps?
DevOps consulting & implementation services include assessment, roadmap planning, and hands-on setup of pipelines, IaC, observability, and automation. Managed DevOps comes after implementation and focuses on ongoing support, monitoring, infrastructure operations, platform maintenance, and sometimes incident response.
How do DevOps implementation services reduce deployment risk during cloud migration?
They reduce deployment risk by standardizing environments, automating tests, adding security gates, improving rollback paths, and creating clear release workflows. Observability also helps teams detect issues earlier, while runbooks and incident processes reduce recovery time when something goes wrong.
How do I evaluate DevOps implementation services provider companies?
Evaluate DevOps implementation services provider companies by looking at real deliverables, not promises. Ask for examples of CI/CD pipelines, IaC modules, observability dashboards, security controls, documentation, and handover plans. Strong providers should also explain KPI baselines, rollback strategy, and first-90-day priorities.
What DevOps metrics should we track before and after implementation?
Track deployment frequency, lead time for changes, change failure rate, MTTR, rollback frequency, SLO compliance, failed deployment rate, incident volume, and automation coverage. Baseline these before implementation so you can prove progress and identify the next delivery bottleneck.
Should DevSecOps start before or after cloud migration?
DevSecOps should start before and continue throughout cloud migration. Identity, secrets, access controls, policy guardrails, and security scanning affect every workload you move. Starting early prevents inconsistent patterns, reduces audit risk, and keeps security from becoming a late release blocker.
Is DIY DevOps enough for growing software teams?
DIY DevOps can work for small teams with strong platform skills and limited scope. But as teams, services, and cloud complexity grow, DIY efforts often create tool sprawl, partial automation, weak documentation, and inconsistent ownership. Expert-led implementation can reduce rework and speed up adoption.
What are the most common DevOps implementation challenges?
Common challenges include resistance to new workflows, tool complexity, siloed ownership, partial automation, skill shortages, legacy dependencies, security gaps, and poor documentation. These issues are manageable when teams start with assessment, clear ownership, phased rollout, proper enablement, and measurable success criteria.









