
TL;DR / Key Takeaways
- Choose an in-house AI team when AI is part of your long-term product moat, your roadmap is stable enough to justify specialized hiring, and you are prepared to support data engineering, platform operations, evaluation, and security over time.
- Choose a partner-led model when speed matters, your internal team is lean, or you need specialist skills in LLMs, RAG, evaluation, and MLOps that would take too long or cost too much to assemble from scratch. Tech hiring is still slow, and specialist compensation remains expensive.
- For many SaaS companies, the strongest answer is hybrid: keep product ownership, domain expertise, and governance in-house while using external specialists to accelerate delivery.
- Treat outsourcing AI development differently from standard software outsourcing. If there is no evaluation plan, monitoring approach, or data-governance model, the work is still in demo territory.
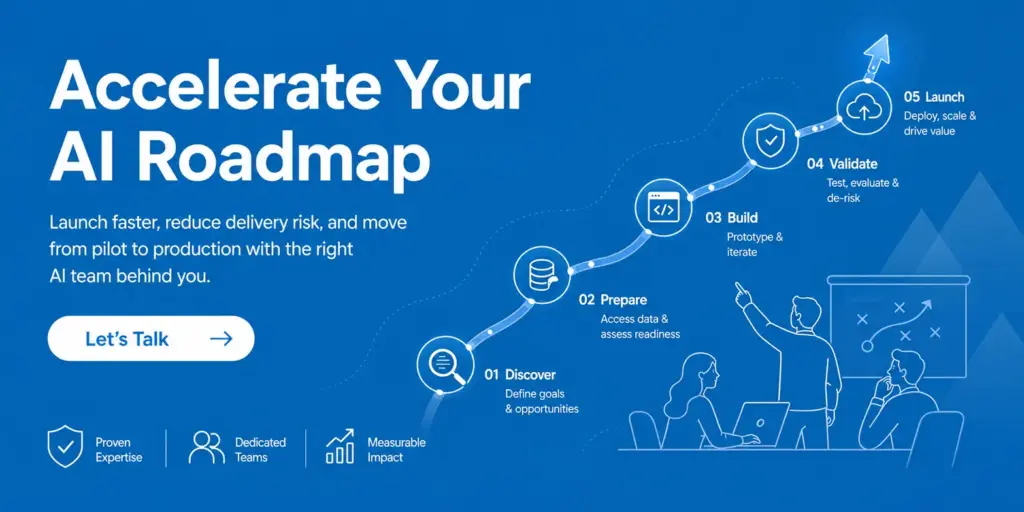
Choosing between an AI development partner and an internal build is not the same as choosing between outsourcing and hiring for a standard SaaS feature. AI systems are probabilistic, data-dependent, and operationally “alive” after launch, which means your real trade-off is not only budget. It is speed to learning, control over the stack, and the level of delivery risk your team can absorb.
If you already know AI matters but are unsure how to execute, one practical starting point is to review BrainX’s AI Development Services page to see what end-to-end support should actually include before you commit to either model.
What An AI Development Partner Actually Does (and What They Don’t)
An AI development partner should do much more than connect an API and ship a polished interface. In a mature engagement, the scope includes problem framing, data-readiness review, architecture selection, evaluation design, deployment planning, monitoring, and governance. What a serious partner should not do is sell “AI magic,” promise accuracy without an evaluation method, or hand over a proof of concept with no path to production.
The useful signal is whether the offer spans strategy, build, deployment, and operational support rather than model access alone.
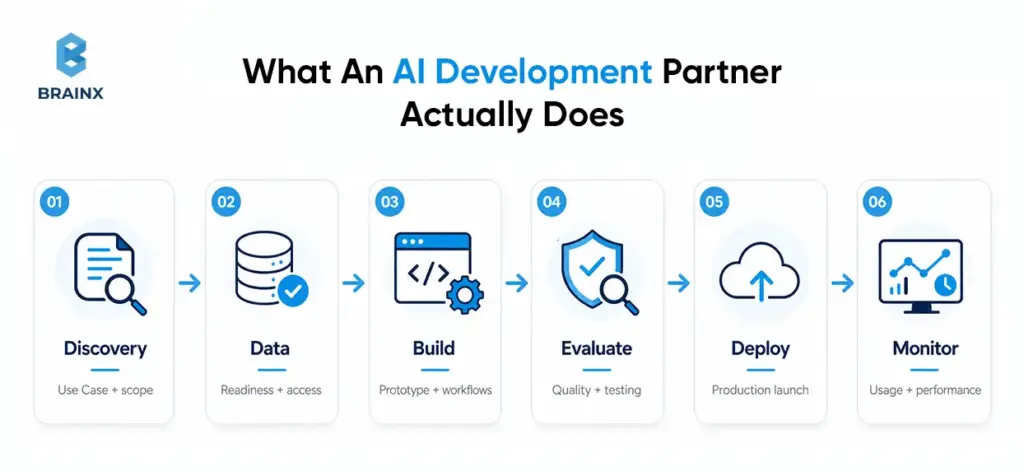
Typical Deliverables (PoC, MVP, Production-Grade AI)
The healthiest way to set expectations is by stage. A PoC should prove feasibility and define a baseline. An MVP should add a working workflow, clear success criteria, instrumentation, and a cost model. Production-grade AI should include deployment pipelines, runbooks, rollback paths, access controls, monitoring, and handover documentation. That is how you avoid the classic PoC trap: impressive output, no operational system.
The broader scope matters because the right operating model is easier to judge when you know what “delivery” actually includes at each stage. A simple way to make that concrete is to separate the work into three practical stages:
- PoC / Prototype: proves feasibility on sample data
- MVP: usable workflow integrated into a pilot environment
- Production AI System: scalable infrastructure, monitoring, maintenance, and handover
Engagement Models (Project Team, Dedicated Squad, AI Assisted Development Partner)
There are usually three practical models. A project team works best for narrow scope and fixed outcomes. A dedicated squad fits a multi-quarter roadmap with integrations and continuous improvement. An AI assisted development partner model sits in the middle: your internal leaders keep direction and decision-making authority while external specialists add the scarce delivery muscle around evaluation, architecture, and LLMOps.
An AI assisted development partner can also augment an internal team with architecture guidance, curated AI workflows, and co-development support rather than taking over the full build. We are making that distinction because many teams do not need full outsourcing. They need targeted acceleration around the parts of AI delivery that are hardest to hire for internally.
In-House AI Team: When It’s the Right Choice
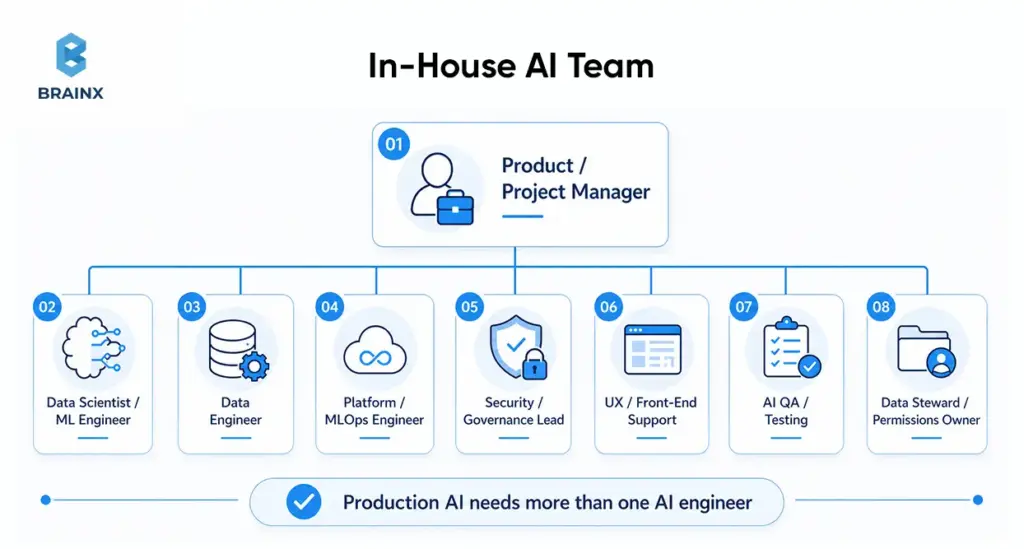
An in-house AI team is the right choice when AI is central to your product differentiation, tightly linked to proprietary workflows, or embedded in a regulated decision path you expect to own for years. The hiring challenge is real, though. The World Economic Forum says skill gaps are the biggest barrier to transformation for 63% of employers, while AI and big data remain the fastest-growing skills category.
Minimum Viable Roles (PM, DS/ML, Data Eng, Platform/MLOps, Security)
A realistic in-house setup usually needs more than one “AI engineer.” At minimum, most teams need a product owner or PM, applied AI or ML capability, data engineering support, platform or MLOps ownership, and security or compliance involvement.
The U.S. Bureau of Labor Statistics continues to project strong growth for data scientists, information-security analysts, software developers, database roles, and computer and information research scientists—all signs that the supporting roles around AI are not optional overhead, but part of the real staffing picture.
For user-facing AI products, teams often also need UX or front-end support, AI QA, and a data steward or permissions owner. This is where many teams underestimate the build. The challenge is not only finding AI talent. It is covering the surrounding operational roles that make the system usable in production.
A practical in-house team often includes:
- Product or Project Manager
- Data Scientist or ML Engineer
- Data Engineer
- Platform or MLOps Engineer
- Security or Governance Lead
- UX or Front-End Support for User-Facing Systems
- QA or Testing Support for AI Behaviors
- Data Steward or Custodian for Permissions and Access
And that staffing picture only tells part of the story. Even a well-hired team still has to support the systems around the model.
The Hidden Work: Data Pipelines, Evaluation Harnesses, Monitoring
The expensive part of AI often sits outside the model. The operational burden includes data ingestion, permissions, data quality, retrieval quality, prompt and model regression tests, observability, alerting, and incident response.
Google Cloud’s MLOps guidance explicitly treats automation and monitoring as required across integration, testing, release, deployment, and infrastructure management, while Microsoft’s guidance for generative AI emphasizes production telemetry and evaluation beyond the original build.
Without reliable dashboards, alerting, and rollback paths, even a promising system can decay after launch as data, usage patterns, or model behavior shift over time.
Common In-House Failure Modes
The pattern is familiar. The model looks strong in a notebook, then weakens under real permissions, data quality, latency budgets, and user behavior. Those gaps usually do not show up all at once. They appear as a series of predictable failure patterns once the work moves beyond the prototype phase.
Common failure modes include:
- Works In Notebook, Fails In Production
- Data Access Delays
- Lack Of Evaluation
- No Governance Or Unclear Ownership
- Burnout And Turnover
For a related internal read, BrainX’s IT Staff Augmentation in Software Development and Detailed IT Staff Augmentation Handbook are useful references for team-shape decisions once you know which roles truly need to stay internal.
AI Development Partner: When It’s the Better Move
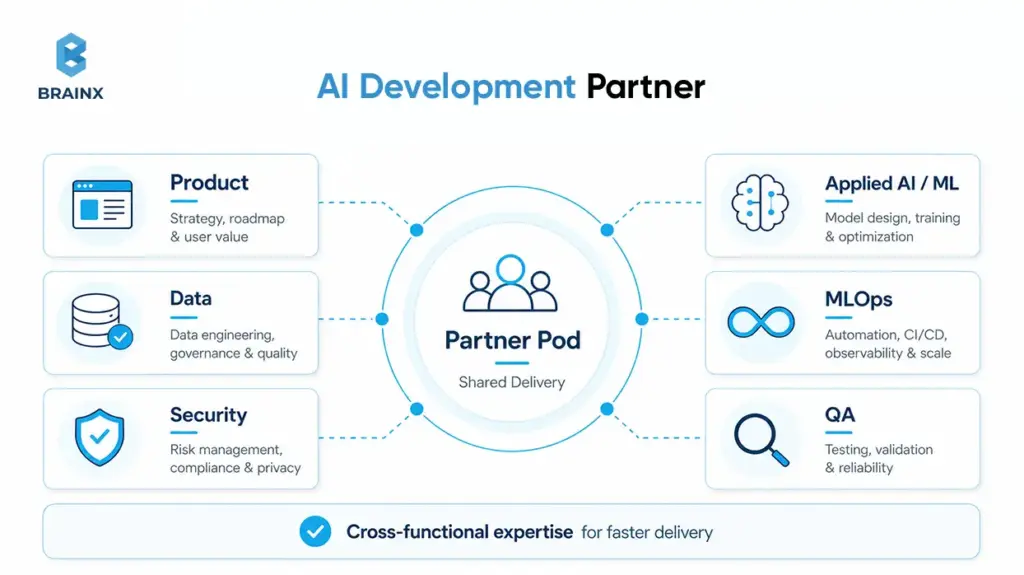
An AI development partner is usually the better move when the business needs speed, the use case is clearly valuable, and internal capacity is constrained. It is especially effective for SaaS teams that need to validate one or two high-value workflows before deciding whether permanent hiring is justified. Median tech hiring times remain long, and ML compensation is still materially above the average software hiring profile.
The strongest signal is usually not company size. It is the combination of urgency, internal bandwidth, and how much specialized capability the use case requires right now.
A partner-led model is especially useful when:
- deadlines are tight
- the work spans multiple AI disciplines
- you need temporary burst capacity
- predictable phased engagement is easier than immediate hiring
Speed To MVP And Faster Iteration Cycles
The biggest partner advantage is not lower hourly cost. It is the compression of time-to-value. A capable external team begins with reusable discovery formats, architecture patterns, evaluation templates, and sprint rituals. That matters when tech hiring alone can consume weeks before a team even starts learning.
Our public process emphasizes requirement gathering, risk evaluation, sprint-based delivery, testing, and post-launch support—exactly the pieces that shorten the path from idea to measurable baseline.
The speed advantage usually comes from reusable patterns, pre-built delivery workflows, and a team that can start learning immediately instead of spending months assembling capability. While that advantage becomes clearer once you look at what partners compress in the first place.
Access To Specialized Skills (LLMs, RAG, MLOps/LLMOps, Evaluation)
Most product teams do not already have deep expertise in retrieval tuning, agent evaluation, groundedness testing, tool-use validation, prompt regression, or model routing. A good partner brings those specialties together instead of forcing you to hire them one by one.
De-Risking Delivery With Established Playbooks
Partner-led delivery also reduces risk by bringing playbooks for discovery, architecture review, security controls, testing, and handover. That does not remove your internal obligations around access, approvals, or data cleanup, but it does lower the chance of avoidable mistakes. A strong partner should be able to explain when retrieval is enough, when fine-tuning is unnecessary, where human review belongs, and what “done” means in evaluation terms before anything reaches production.
AI Development Partner Vs In-House Team
If you are comparing an AI development partner with an internal team, the right answer depends less on ideology and more on operating context: do you need speed, long-term ownership, scarce specialist skills, or stricter control around regulated data? The matrix below is a practical synthesis of current hiring, MLOps, monitoring, and security guidance.
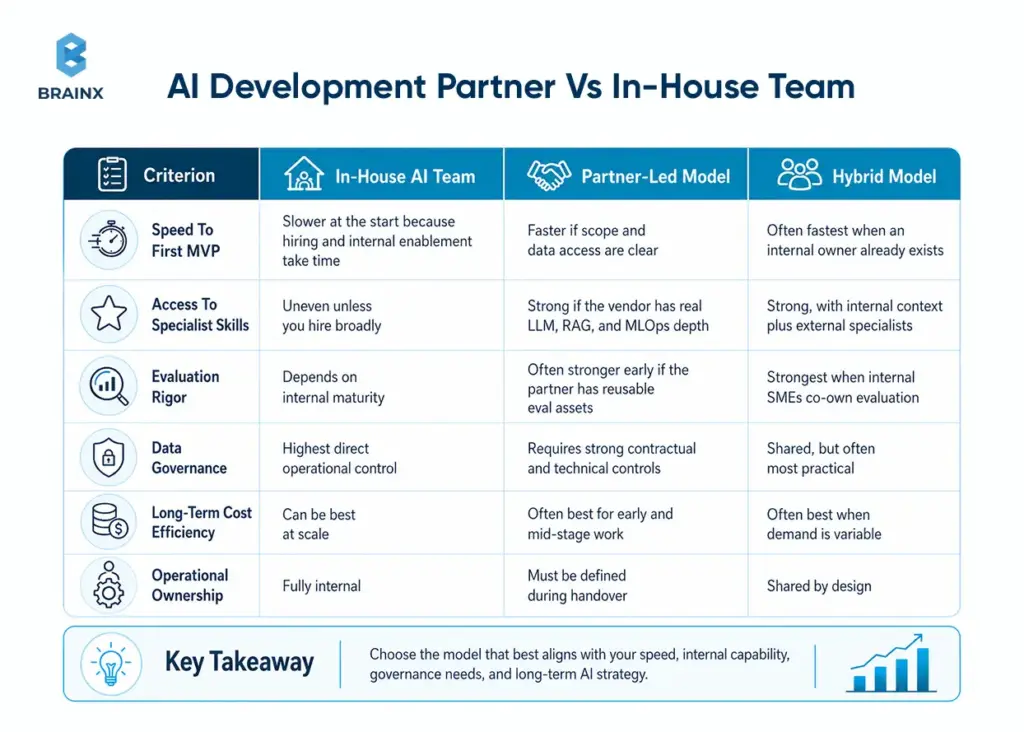
This comparison aligns with public guidance on tech hiring timelines, current specialist salary levels, the operational requirements in MLOps and GenAI monitoring, and the way AI infrastructure pricing compounds as usage grows.
It is also where many teams misread the economics. AI delivery costs rarely sit in one line item. It usually means budgeting not just for salaries or vendor fees, but also for recruiting time, cloud usage, data labeling, vector search, monitoring, software licenses, and ongoing maintenance.
What Are the Best Alternatives to LLMOps Consultancy vs In-House Team?
Hybrid co-sourcing, managed LLMOps platforms, fractional AI leadership, freelance AI architects, open-source LLMOps stacks, and automated AI tools or agents are the best alternatives to LLMOps consultancy vs in-house teams. These models are useful for businesses to consider when making decisions about their speed, cost, control and internal capacity in the long term.
A full in-house LLMOps team provides high control, but can be costly and time-consuming to establish. A traditional consultancy can provide fast expertise, but it may reduce internal ownership if knowledge transfer is weak. A middle-ground model is often a better idea for many companies, as it involves keeping strategy in-house while leveraging external expertise and platforms or automation as necessary.
Hybrid Co-Sourcing Or Embedded LLMOps Teams
Hybrid co-sourcing allows you to integrate external LLMOps experts into your current team. They collaborate with your developers, fit into your systems and processes, and support the development of systems within your own environment.
This is the preferred solution for companies that have engineers already in place but may not be very experienced with LLMOps. It enables quicker deliveries and allows internal teams to learn about RAG pipelines, model monitoring, evaluation workflows, deployment systems, and observability.
Best for: Companies that wish to have custom LLMOps infrastructure but do not wish to fully outsource ownership.
Managed LLMOps Platforms
Managed LLMOps platforms support teams to deploy, monitor, test, and scale LLM applications without having to manually build each infrastructure layer. These platforms may support prompt testing, model evaluation, observability, hosting, workflow orchestration, and data pipeline management.
They are useful for startups and mid-sized teams that need speed. The primary challenge is platform dependency, so it is important that companies should plan their architecture carefully.
Best for: Teams that want faster deployment and lower infrastructure complexity.
Fractional AI Leadership
You can have a fractional AI leader, AI architect, CTO or CAIO who can steer the strategy without being a full-time employee. This person helps with model selection, LLM governance, security planning, data architecture, evaluation standards, and implementation direction.
Suitable for: A company that has developers, but lacks experience in making senior AI decisions.
Freelance AI Architects
Freelance AI architects are useful for early planning, audits, vendor selection, and technical validation. They can be critical in determining if the company should implement RAG, fine-tuned models, open source models, managed platforms or custom infrastructure.
This is a good choice but can be insufficient for long-term execution.
Works for: Early-stage planning, architecture review, or technical audits.
Open-Source LLMOps Stack
An open-source LLMOps stack usually encompasses tools to trace, evaluate, manage prompts, orchestrate, monitor and manage model lifecycles. This provides more control and minimizes the vendor lock-in problem, but it does require that you have solid DevOps/engineering skills within your organization.
Best for: Technical teams that want ownership and flexibility.
Automated AI Tools And AI Agents
AI tools and agents can support testing, monitoring, alerting, evaluation, and repetitive operational tasks. They can decrease human workload but they are not meant to entirely replace humans.
Best for: Teams looking to automate the routine work of LLMOps while keeping humans in the loop.
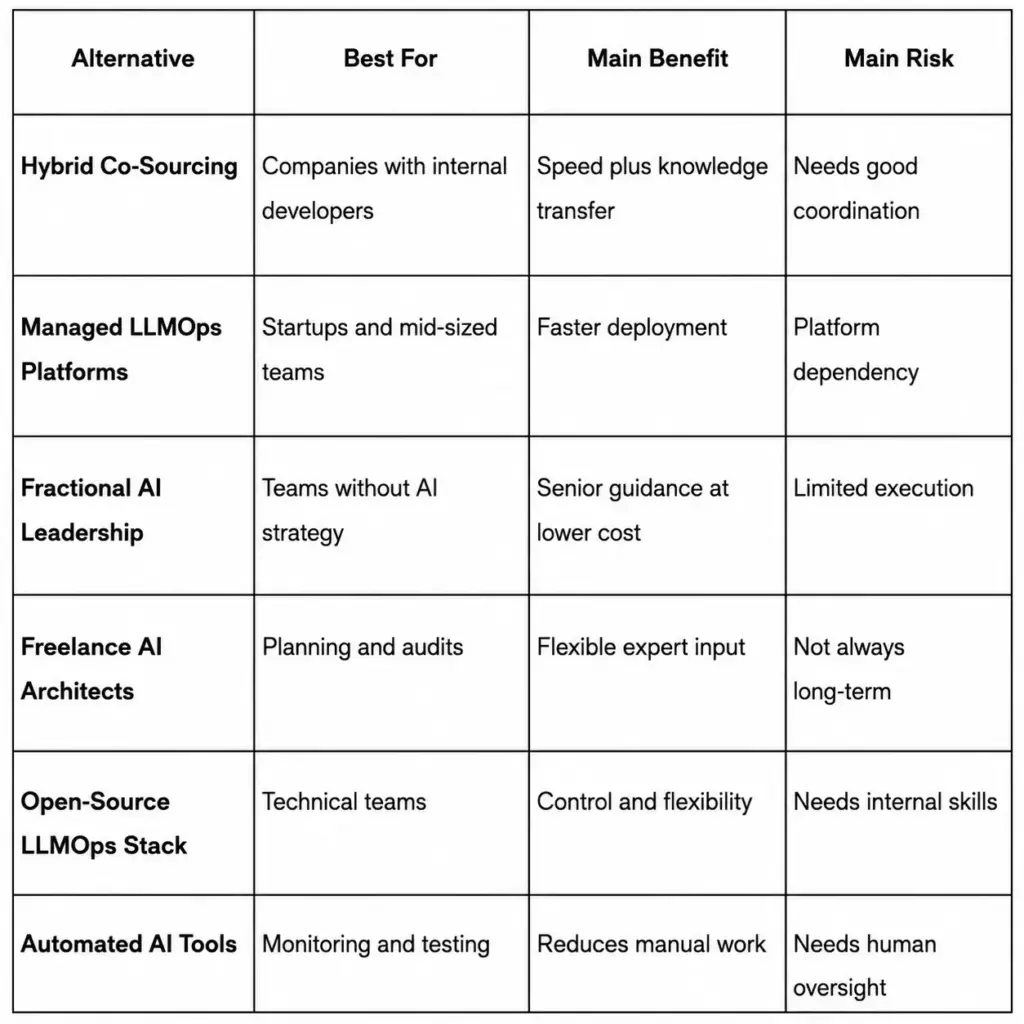
Once you understand these alternative options, the next step is to compare their real cost beyond headline rates, such as hiring time, tooling, infrastructure, monitoring and ownership over the long term.
Cost (TCO), Not Just Rates
Total cost of ownership should include recruiting time, compensation, management overhead, cloud spend, retrieval infrastructure, observability, experimentation, compliance, and maintenance. Current salary benchmarks still put mid-level ML engineers roughly in the low-to-high six figures and senior talent higher, while model, vector search, and observability vendors all layer usage-based costs on top.
Time-To-Value And Delivery Risk
Time-to-value in AI depends on more than coding speed. Environment readiness, clean data access, stakeholder alignment, and experiment velocity are usually the bigger variables. A partner can reduce risk because the team is already assembled, but no partner can erase delays caused by missing permissions, unclear KPIs, or slow internal sign-off.
Control, IP, And Security
In-house teams offer more direct day-to-day control, but partner-led work can still be secure and contractually clean if IP ownership, approved tooling, access rules, logging, retention, and secure SDLC expectations are documented up front. The AICPA frames SOC 2 against security, availability, processing integrity, confidentiality, and privacy, while ISO/IEC 27001 defines requirements for an information security management system. On the AI-specific side, Amazon Web Services guidance emphasizes least-privilege access across models, data stores, endpoints, and agent workflows.
Quality Evaluation, Testing, And Monitoring
AI quality is not “did the demo work.” It is whether the system meets offline metrics, human evaluation thresholds, regression tests, safety requirements, and production monitoring standards over time. NIST’s AI RMF centers this around govern, map, measure, and manage, while Microsoft’s current evaluator stack goes beyond output quality to tool selection, tool-call accuracy, groundedness, and task completion.
By this point, the pattern is usually clear: the real decision is rarely binary.
The Hybrid Model (Often The Best Answer)
For many SaaS businesses, the most practical answer is hybrid. Keep strategy, product vision, domain context, data stewardship, and governance inside the company. Add a partner pod to accelerate architecture, implementation, integration, and evaluation.
BrainX’s own team-model guidance makes the same distinction: direction can stay in-house while execution is extended externally with clear ownership for architecture, QA, and reporting.

What To Keep In-House Vs Delegate To A Partner
Keep product strategy, customer understanding, domain nuance, data stewardship, legal review, and final security sign-off in-house. Delegate delivery acceleration, architecture spikes, evaluation harness setup, integration-heavy implementation, experimentation, and documentation support to the partner. That split preserves accountability without forcing the business to hire every niche role on day one.
How To Structure A “Partner Pod” Around Your Core Team
Make the operating model explicit. Assign one internal product owner, one technical owner, one data owner, and one executive sponsor. Establish weekly demos, a shared decision log, clear acceptance criteria, and a written handover plan. BrainX’s public process and team-model guidance both put documentation, evaluation instructions, and change management on the table—which is exactly what keeps hybrids from degrading into ambiguity.
How To Choose An AI Development Partner (Scorecard + Red Flags)
If your next step is figuring out how to choose an AI development partner, do not start with polished demos or portfolio screenshots. Start with delivery maturity. The real test is whether the vendor can explain how they frame the problem, validate quality, control model risk, and transfer operational ownership without creating permanent dependency.
A practical scorecard is simple: rate each vendor from 1–5 on domain fluency, data-security posture, evaluation maturity, architecture judgment, LLM/MLOps depth, delivery process, and handover quality. A team can be imperfect on one or two items, but anything weak on evaluation, security, or handoff should be treated as procurement risk.

Technical Signals To Verify (Not Just Portfolio Screenshots)
Ask for architecture decisions, evaluation artifacts, monitoring examples, and incident-handling logic. A capable team should be able to show how they measured relevance or groundedness, how they test tool use, what telemetry they collect, and what rollback path they follow if quality or cost worsens after a release. Portfolio visuals do not answer any of those questions; evaluation and operations artifacts do.
Data & Security Questions (Must-Answer)
Ask where data is stored and processed, how PII is handled, which third-party tools are involved, who can access prompts and logs, how retention works, and whether vendor policies allow data exclusion from training or logging. This is not theoretical. OpenAI documents up to 30-day default abuse-monitoring retention for API usage, with modified or zero-data-retention controls for eligible customers, while Microsoft states that Azure OpenAI does not use customer data to retrain models and supports private networking. Those are the kinds of specifics your partner should already know and map to your environment.
You should also ask how the partner maps its controls to SOC 2 criteria, ISO/IEC 27001, least-privilege access, vendor approval processes, and your sector’s own compliance obligations. If the security conversation never gets more concrete than “we take privacy seriously,” move on.
Delivery Process Questions (Discovery → Build → Validate → Deploy)
Ask what happens before the build starts. What artifacts come out of discovery? What baseline is used for comparison? What evaluation set exists before prompting is tuned? What marks the MVP as ready? What documentation and runbooks are included at handover? Good teams can define a real “definition of done” for AI, not just a list of shipped tickets.
Red Flags
Red flags are usually obvious once you know what to look for: guaranteed accuracy with no evaluation plan, vague answers about data handling, no monitoring story, no rollback path, no named owner for post-launch support, and no explanation of how prompt or model changes are regression-tested. Another warning sign is a team that only talks about the model and never about the surrounding system, the threat model, or the operational lifecycle.
Implementation Plan: Your First 30–90 Days With A Partner (or Building In-House)
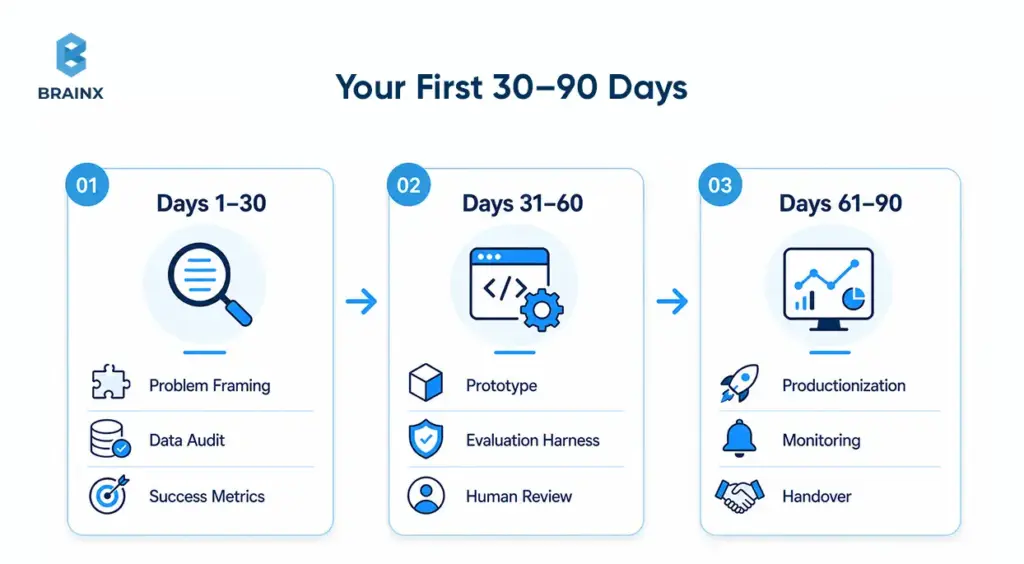
Once you choose a path, the first 90 days should reduce uncertainty in the right order. Whether you work with an AI development partner or build internally, the sequence should be: frame the problem, audit the data, define success, build the smallest useful baseline, then productionize only what has been validated. That order mirrors both BrainX’s public process and broader MLOps guidance.
Days 1–30 — Problem Framing, Data Audit, Success Metrics
Use the first month to define the workflow, business KPI, user path, data sources, risks, and decision-makers. Create the evaluation plan before writing much code. Identify which integrations, approvals, and security reviews could block progress. If nobody can state the success metric clearly, the build is not ready.
Days 31–60 — Prototype + Evaluation Harness
In the second phase, build the smallest workflow that can be measured against a baseline. Add tracing, guardrails, feedback capture, and human review where the cost of error matters. Microsoft’s current evaluator guidance is useful here because it pushes teams to assess not only answer quality, but also tool selection, tool accuracy, task completion, and groundedness.
Days 61–90 — Productionization (MLOps/LLMOps), Monitoring, Handover
Only after the baseline proves value should you harden the system. Add deployment discipline, alerting, access controls, SLAs where needed, support runbooks, regression testing, and a handover model. This is also where retraining or prompt-change ownership should be assigned explicitly if the use case requires frequent updates.
Cost & Budgeting: What This Decision Really Costs
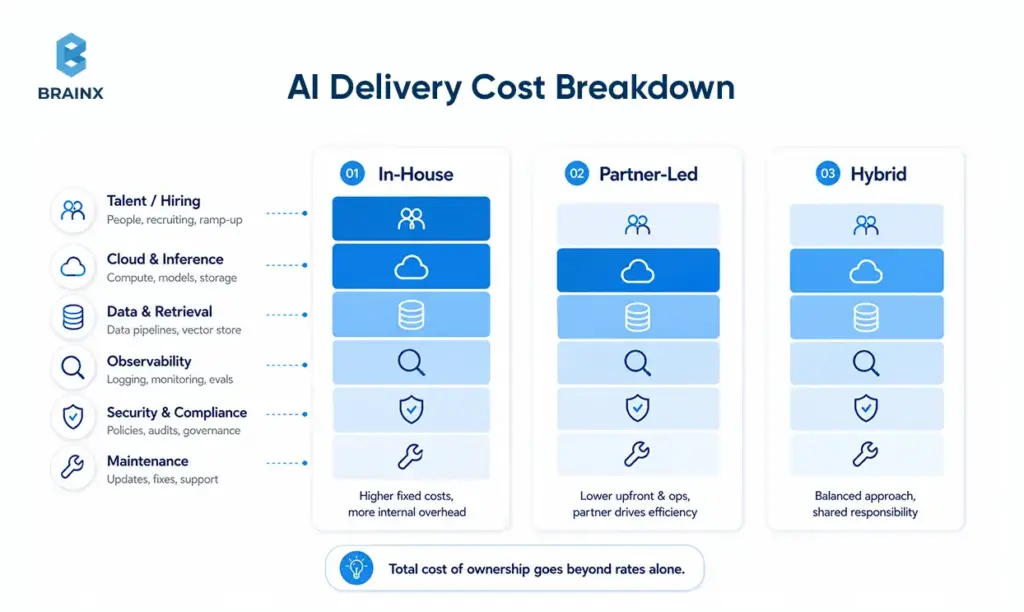
AI budgeting gets distorted when leaders focus on daily rates or token prices in isolation. In practice, the costs land across people, time, retrieval infrastructure, observability, security, and integration-heavy delivery. That is why even as the Stanford HAI AI Index documents sharp drops in inference cost over the last two years, real project budgets can still expand once usage, support, and operational discipline grow.
Key Cost Drivers In AI Projects
The big cost drivers are usually data labeling or cleanup, vector search, inference usage, observability, security controls, and integrations with the rest of your stack. Pricing pages from OpenAI, Azure AI Search, and Google Cloud Observability all show why: model usage is token-based or throughput-based, search scales with storage and throughput, and monitoring scales with data volume. Vendors such as Pinecone also add a dedicated retrieval cost layer for production applications.
Budget Ranges By Stage (PoC Vs MVP Vs Production)
As a directional planning heuristic—an inference from 2026 hiring benchmarks, tech recruiting timelines, cloud and model pricing, and BrainX’s own stage-based cost guidance—many SaaS teams budget roughly $25k–$75k for a narrow PoC, $75k–$200k for an MVP that reaches real users, and $200k+ for production AI with integrations, governance, monitoring, and handover. If the work involves regulated data, voice, complex retrieval, or heavy back-office integration, the range can move materially higher.
Common Mistakes To Avoid (In-House And Partner-Led)
The fastest way to waste AI budget is to treat the project like a normal feature build. The second fastest way is to hire or outsource before anyone has defined what “good” actually means in quality, risk, and operating terms.
Skipping Evaluation And Shipping “Demo AI”
A persuasive demo can hide weak reliability. If you do not define test sets, human-review criteria, failure thresholds, and business KPIs, you are not validating the product. You are reacting to anecdotes. Modern evaluator stacks exist because output quality alone is not enough.
Underestimating Data Readiness
Teams often assume they can “figure out the data later.” In reality, missing permissions, inconsistent source quality, fragmented knowledge bases, and weak taxonomy are among the most common reasons AI projects stall or underperform. AWS’s GenAI data guidance is blunt here: sensitive-data controls, governance, and data-quality discipline have to be built into the lifecycle early.
No Monitoring Plan (Quality, Drift, Cost)
If nobody is watching quality, latency, safety events, and cost after launch, users will discover production problems before your team does. That is expensive and avoidable. Google’s MLOps guidance and Microsoft’s monitoring playbook both treat telemetry as part of the system, not a nice-to-have add-on.
Unclear Ownership (Who Maintains What After Launch)
Many projects fail not because the MVP was bad, but because no one owns the system after release. Decide who owns prompts, vendors, regressions, incident response, and roadmap changes before handover. BrainX’s team-model and process documentation are helpful reminders that architecture docs, runbooks, evaluation instructions, and change management are part of the deliverable.
How BrainX Helps With AI Development Partner-Led Delivery
BrainX positions its AI offering around discovery, readiness, architecture, build, deployment, and ongoing support rather than around isolated model work. That is the right shape for buyers who want measurable progress without having to build every specialist capability internally from day one.
What You Get (Discovery, Build, Eval, Deploy, Handover)
A credible partner-led engagement should include structured discovery, scoped architecture, implementation, evaluation, deployment planning, documentation, and handover support. On the BrainX side, the public AI pages explicitly include strategy and advisory, generative AI delivery, RAG, integration, and AI DevOps/MLOps—plus process pages that show requirement gathering, risk evaluation, testing, and launch support.
Typical Engagement Options (Pilot → MVP → Scale)
The most practical engagement path is staged: align on the problem, run a focused pilot, expand to MVP once evaluation is credible, then scale with tighter governance and operations. BrainX’s newer AI content and process pages describe that progression clearly, from discovery to PoC to MVP to production support.
Proof Points (Case Studies, Metrics, Testimonials)
The strongest proof is specific outcomes. BrainX’s Copyright Clinic case study states the platform enabled 24/7 AI triage and cut intake time by 80%. Another example is 15% beta-retention lift and a 4.6 App Store rating for the Ponder App, alongside our client’s feedback that emphasizes speed, testing, design, and QA support. Those are the kinds of signals buyers should look for in any vendor. Go for measurable outcomes and not just polished screenshots.
FAQs About Choosing an AI Development Partner
What is an AI development partner?
An AI development partner is an external team that helps a company move from use-case definition to data readiness, architecture, evaluation, deployment, and post-launch operations. The best partners do not just build a prototype. They help you ship something that can be measured, governed, and maintained.
Is an AI development partner cheaper than hiring an in-house AI team?
Often, yes in the first phase, but not always over the long term. If your roadmap is stable and AI becomes a core competency, internal hiring can become more efficient. If demand is variable or you need specialist skills quickly, partner-led delivery often lowers both cost and execution risk because you avoid long hiring cycles and immediate fixed headcount.
How do I choose an AI development partner for my industry (Healthcare/Fintech/Retail)?
If you are working through how to choose an AI development partner for healthcare, fintech, or retail, start with domain reality, not generic AI claims. In healthcare, ask about privacy, human review, and sensitive-data handling. In fintech, ask about auditability, access control, and failure modes. In retail, ask about integrations, search quality, experimentation cadence, and cost-per-query economics. Then verify that the partner can show relevant architecture and evaluation examples, not just sector logos.
What should I ask before signing with an AI assisted development partner?
Ask about data handling, evaluation methodology, monitoring, incident response, documentation, handover, model and vendor dependencies, and IP ownership. With an AI assisted development partner, the key question is not “Can you build it?” It is “Can you build it in a way my team can trust and operate later?”
How long does it take to build an AI MVP with a partner vs in-house?
A partner can often start discovery immediately because the team is already assembled, while internal teams may spend weeks on hiring and enablement first. Actual build time still depends heavily on data access, environment readiness, and stakeholder alignment, but partner-led MVPs usually reach a measurable baseline faster when the use case is already defined.
How do IP, Data Privacy, and Security work when partnering on AI development?
The right answer is contractually and technically, before work begins. IP ownership, data retention, logging, approved vendors, encryption, access control, model-training restrictions, and handover obligations should all be documented. Use SOC 2 and ISO/IEC 27001 as baseline control language, then add AI-specific requirements around least privilege, prompt and log access, residency, and vendor-specific data controls.










